Departition components combine multiple flow partitions of data records into a single flow as follows
Concatenate:
Concatenate appends multiple flow partitions of data records one after another
- Reads all the data records from the first flow connected to the in port (counting from top to bottom on the graph) and copies them to the out port.
- Then reads all the data records from the second flow connected to the in port and appends them to those of the first flow, and so on
GATHER:
Gather combines data records from multiple flow partitions arbitrarily
Gather is used to:
Gather combines data records from multiple flow partitions arbitrarily
Gather is used to:
- Reduce data parallelism, by connecting a single fan-in flow to the in port
- Reduce component parallelism, by connecting multiple straight flows to the in port
The Gather component:
- Reads data records from the flows connected to the in port.Combines the records arbitrarily.
- Writes the combined records to the out port.
INTERLEAVE:
Interleave combines blocks of data records from multiple flow partitions in round-robin fashion
Parameter :
blocksize
(integer, required)
Number of data records Interleave reads from each flow before reading the same number of data records from the next flow.
Default is 1.
Interleave combines blocks of data records from multiple flow partitions in round-robin fashion
Parameter :
blocksize
(integer, required)
Number of data records Interleave reads from each flow before reading the same number of data records from the next flow.
Default is 1.
- Reads the number of data records specified in the blocksize parameter from the first flow connected to the in port
- Reads the number of data records specified in the blocksize parameter from the next flow, and so on
- Writes the records to the out port
MERGE:
Merge combines the data records from multiple flow partitions that have been sorted based on the same key specifier, and maintains the sort order
Parameter:
Key :Name of the key(primary key or unique key) field for combine the data .the key maybe more than one .
1 .Read the records from the in port and combine the records based on the sorting order
Merge combines the data records from multiple flow partitions that have been sorted based on the same key specifier, and maintains the sort order
Parameter:
Key :Name of the key(primary key or unique key) field for combine the data .the key maybe more than one .
1 .Read the records from the in port and combine the records based on the sorting order
Sort components
Checkpoint sort:
It sorts and merges data records, inserting a checkpoint between the sorting and merging phases
FIND SPLITTERS:
Find splitters sorts data records according to a key specifier, and then finds the ranges of key values that divide the total number of input data records approximately evenly into a specified number of partitions.
Parameter:
key
(key specifier, required)

Name(s) of the key field(s) and the sequence specifier(s) required to Find Splitters to use when it orders data records and sets splitter points.
Number of partitions
(Integer, required)
Number of partitions into which you want to divide the total number of data records evenly.
The output from the out port of Find Splitters to the split port of PARTITION BY RANGE.
Rules to use Find splitter:
Number of partitions
(Integer, required)
Number of partitions into which you want to divide the total number of data records evenly.
The output from the out port of Find Splitters to the split port of PARTITION BY RANGE.
Rules to use Find splitter:
- Use the same key specifier for both components.
- Make the number of partitions on the flow connected to the out port of Partition by Range the same as the value in the num_partitions parameter of Find Splitters.
If n represents the value in the num_partitions parameter, Find Splitters generates n-1 splitter points. These points specify the key values that divide the total number of input records approximately evenly into n partitions.
You do not have to provide sorted input data records for Find Splitters. Find Splitters sorts internally.
Find Splitters:
You do not have to provide sorted input data records for Find Splitters. Find Splitters sorts internally.
Find Splitters:
- Reads records from the in port
- Sorts the records according to the key specifier in the key parameter
- Writes a set of splitter points to the out port in a format suitable for the split port of Partition by Range
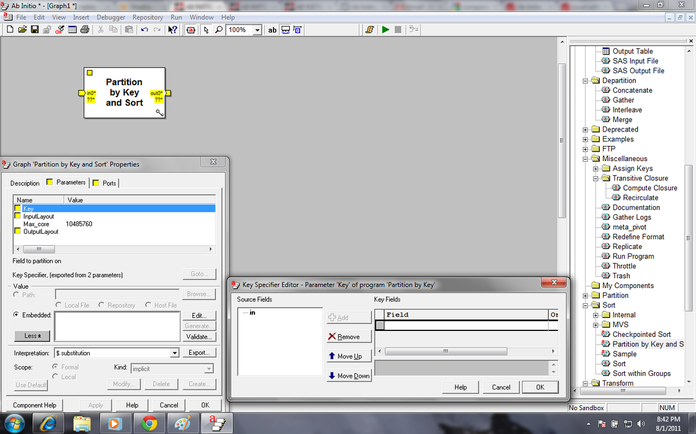
Partition by KEY and Sort:
A partition by key component is generally followed by a sort component. If the partitioning key and sorting key is the same instead to using those two components partition by key and sort component should be used
In this component also key and max-core value has be mentioned as per same rule of sort component
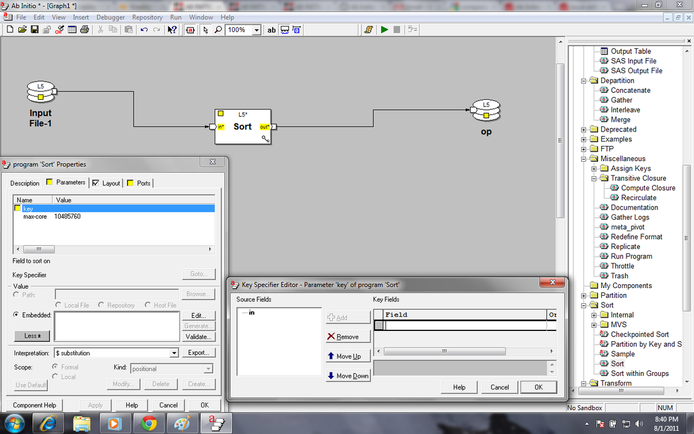
Sort
Sort component sort the data in ascending or descending order according to the key specified.
By default sorting is done in ascending order. To make the flow in descending order the descending radio button has to be clicked.
In the parameter max-core value is required to be specified. Though there is a default value, it recommended to use $ variable which is defined in the system [$MAX_CORE, $MAX_CORE_HALF etc].
A partition by key component is generally followed by a sort component. If the partitioning key and sorting key is the same instead to using those two components partition by key and sort component should be used
In this component also key and max-core value has be mentioned as per same rule of sort component
Sort
Sort component sort the data in ascending or descending order according to the key specified.
By default sorting is done in ascending order. To make the flow in descending order the descending radio button has to be clicked.
In the parameter max-core value is required to be specified. Though there is a default value, it recommended to use $ variable which is defined in the system [$MAX_CORE, $MAX_CORE_HALF etc].
- Sort stores temporary files Reads the records from all the flows connected to the in port until it reaches the number of bytes specified in the max-core parameter
- Sorts the records and writes the results to a temporary file on disk
- Repeats this procedure until it has read all records
- Merges all the temporary files, maintaining the sort order
- Writes the result to the out port . Sort stores temporary files in the working directories specified by its layout
Sort within Groups:
Sort within Groups refines the sorting of data records already sorted according to one key specifier: it sorts the records within the groups formed by the first sort according to a second key specifier
In parameter part there are two sort keys
1) major key: it is the main key on which records are already sorted.
2) minor key : If the records are already sorted according to major key, according to minor key records are resorted within major key group.
Sort within Groups assumes input records are sorted according to the major-key parameter.
Sort within Groups reads data records from all the flows connected to the in port until it either reaches the end of a group or reaches the number of bytes specified in the max-core parameter.
When Sort within Groups reaches the end of a group, it does the following:
Sort within Groups refines the sorting of data records already sorted according to one key specifier: it sorts the records within the groups formed by the first sort according to a second key specifier
In parameter part there are two sort keys
1) major key: it is the main key on which records are already sorted.
2) minor key : If the records are already sorted according to major key, according to minor key records are resorted within major key group.
Sort within Groups assumes input records are sorted according to the major-key parameter.
Sort within Groups reads data records from all the flows connected to the in port until it either reaches the end of a group or reaches the number of bytes specified in the max-core parameter.
When Sort within Groups reaches the end of a group, it does the following:
- Sorts the records in the group according to the minor-key parameter
- Writes the results to the out port
Repeats this procedure with the next group
Transform components

Aggregate
Aggregate generates data records that summarize groups of data records ( similar to rollup). But it has lesser control over data
Parameter :the following are the parameter for aggregate are sorted-input,key,max- core,transform,select,reject threshold ,ramp,error log,reject log
The input must be sorted before using aggregate .we can use max core parameter or sort component for sort the data .
Aggregate generates data records that summarize groups of data records ( similar to rollup). But it has lesser control over data
Parameter :the following are the parameter for aggregate are sorted-input,key,max- core,transform,select,reject threshold ,ramp,error log,reject log
The input must be sorted before using aggregate .we can use max core parameter or sort component for sort the data .
The Aggregate component:
1. Reads the records from the in port
2. Does one of the following:
• If you do not supply an expression for the select parameter, processes all the records on the in port.
• If you have defined the select parameter, applies the select expression to the records:
3. Aggregates the data records in each group, using the transform function as follows:
a. For the first record of a group, Aggregate calls the transform function with two arguments: NULL and the first record.
Aggregate saves the return value of the transform function in a temporary aggregate record that has the record format of the out port.
b. For the rest of the data records in the group, Aggregate calls the transform function with the temporary record for that group and the next record in the group as arguments.
Again, Aggregate saves the return value of the transform function in a temporary aggregate record that has the record format of the out port.
4. If the transform function returns NULL, Aggregate:
a. Writes the current input record to the reject port.
Aggregate stops execution of the graph when the number of reject events exceeds the result of the following formula:
limit + (ramp * number_of_records_processed_so_far)
For more information, see "Setting limits and ramps for reject events".
b. Writes a descriptive error message to the error port.
5. Aggregate writes the temporary aggregate records to the out port in one of two ways, depending on the setting of the sorted-input parameter:
a. When sorted-input is set to Input must be sorted or grouped, Aggregate writes the temporary aggregate record to the out port after processing the last record of each group, and repeats the preceding process with the next group.
b. When sorted-input is set to In memory: Input need not be sorted, Aggregate first processes all the records, and then writes all the temporary aggregate records to the out port.
Denormalize sorted:
Denormalize Sorted consolidates groups of related data records into a single output record with a vector field for each group, and optionally computes summary fields in the output record for each group. Denormalize Sorted requires grouped input
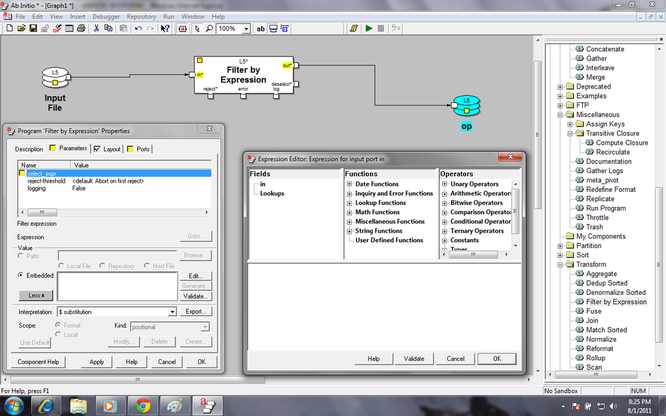
Filter by Expression: Filter by Expression filters data records according to a specified DML expression.
Basically it can be compared with the where clause of sql select statement.
Different functions can be used in the select expression of the filter by expression component even look up can also be used. In this filter by expression there is reject-threshold parameter
The value of this parameter specifies the component's tolerance for reject events. Choose one of the following:
• Abort on first reject — Write Multiple Files stops the execution of the graph at the first reject event it generates.
• Never abort — the component does not stop the execution of the graph, no matter how many reject events it generates.
• Use ramp/limit — the component uses the settings in the ramp and limit parameters to determine how many reject events to allow before it stops the execution of the graph.
The default is Abort on first reject.
Filter by Expression:
1. Reads data records from the in port.
2. Applies the expression in the select_expr parameter to each record. If the expression returns:
• Non-0 value — Filter by Expression writes the record to the out port.
• 0 — Filter by Expression writes the record to the deselect port. If you do not connect a flow to the deselect port, Filter by Expression discards the records.
• NULL — Filter by Expression writes the record to the reject port and a descriptive error message to the error port
FUSE: Fuse combines multiple input flows into a single output flow by applying a transform function to corresponding records of each flow
Parameter :the following are the parameter for fuse are count,transform,select,reject threshold ,ramp,error log,reject log
Fuse applies a transform function to corresponding records of each input flow. The first time the transform function executes, it uses the first record of each flow. The second time the transform function executes, it uses the second record of each flow, and so on. Fuse sends the result of the transform function to the out port.
fuse works as follows:
1. Fuse tries to read from each of its input flows): If all of its input flows are finished, fuse exits.
Otherwise, Fuse reads one record from each still-unfinished input port and a NULL from each finished input port.
2. If Fuse reads a record from at least one flow, Fuse uses the records as arguments to the select function if the select function is present.
• If the select function is not present, Fuse uses the records as arguments to the fuse function.
• If the select function is present, fuse discards the records if select returns zero and uses the records as arguments to the fuse function if select returns non-zero.
3. Fuse sends to the out port the record returned by the fuse function
1. Reads the records from the in port
2. Does one of the following:
• If you do not supply an expression for the select parameter, processes all the records on the in port.
• If you have defined the select parameter, applies the select expression to the records:
3. Aggregates the data records in each group, using the transform function as follows:
a. For the first record of a group, Aggregate calls the transform function with two arguments: NULL and the first record.
Aggregate saves the return value of the transform function in a temporary aggregate record that has the record format of the out port.
b. For the rest of the data records in the group, Aggregate calls the transform function with the temporary record for that group and the next record in the group as arguments.
Again, Aggregate saves the return value of the transform function in a temporary aggregate record that has the record format of the out port.
4. If the transform function returns NULL, Aggregate:
a. Writes the current input record to the reject port.
Aggregate stops execution of the graph when the number of reject events exceeds the result of the following formula:
limit + (ramp * number_of_records_processed_so_far)
For more information, see "Setting limits and ramps for reject events".
b. Writes a descriptive error message to the error port.
5. Aggregate writes the temporary aggregate records to the out port in one of two ways, depending on the setting of the sorted-input parameter:
a. When sorted-input is set to Input must be sorted or grouped, Aggregate writes the temporary aggregate record to the out port after processing the last record of each group, and repeats the preceding process with the next group.
b. When sorted-input is set to In memory: Input need not be sorted, Aggregate first processes all the records, and then writes all the temporary aggregate records to the out port.
Denormalize sorted:
Denormalize Sorted consolidates groups of related data records into a single output record with a vector field for each group, and optionally computes summary fields in the output record for each group. Denormalize Sorted requires grouped input
Filter by Expression: Filter by Expression filters data records according to a specified DML expression.
Basically it can be compared with the where clause of sql select statement.
Different functions can be used in the select expression of the filter by expression component even look up can also be used. In this filter by expression there is reject-threshold parameter
The value of this parameter specifies the component's tolerance for reject events. Choose one of the following:
• Abort on first reject — Write Multiple Files stops the execution of the graph at the first reject event it generates.
• Never abort — the component does not stop the execution of the graph, no matter how many reject events it generates.
• Use ramp/limit — the component uses the settings in the ramp and limit parameters to determine how many reject events to allow before it stops the execution of the graph.
The default is Abort on first reject.
Filter by Expression:
1. Reads data records from the in port.
2. Applies the expression in the select_expr parameter to each record. If the expression returns:
• Non-0 value — Filter by Expression writes the record to the out port.
• 0 — Filter by Expression writes the record to the deselect port. If you do not connect a flow to the deselect port, Filter by Expression discards the records.
• NULL — Filter by Expression writes the record to the reject port and a descriptive error message to the error port
FUSE: Fuse combines multiple input flows into a single output flow by applying a transform function to corresponding records of each flow
Parameter :the following are the parameter for fuse are count,transform,select,reject threshold ,ramp,error log,reject log
Fuse applies a transform function to corresponding records of each input flow. The first time the transform function executes, it uses the first record of each flow. The second time the transform function executes, it uses the second record of each flow, and so on. Fuse sends the result of the transform function to the out port.
fuse works as follows:
1. Fuse tries to read from each of its input flows): If all of its input flows are finished, fuse exits.
Otherwise, Fuse reads one record from each still-unfinished input port and a NULL from each finished input port.
2. If Fuse reads a record from at least one flow, Fuse uses the records as arguments to the select function if the select function is present.
• If the select function is not present, Fuse uses the records as arguments to the fuse function.
• If the select function is present, fuse discards the records if select returns zero and uses the records as arguments to the fuse function if select returns non-zero.
3. Fuse sends to the out port the record returned by the fuse function

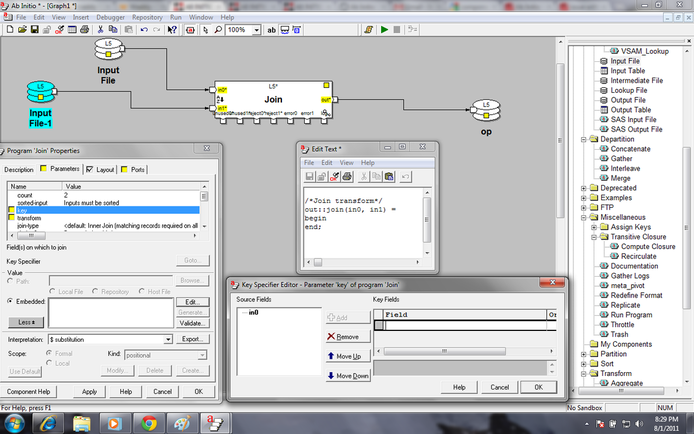
JOIN:
Join reads the records from multiple ports, operates on the records with matching keys using a multiinput transform function and writes the result into output ports
In join the key parameter has to be specified from input flow (either of the flow) ascending or descending order. If all the input flows do not have any common field, override-key must be specified to map the key specified
Join reads the records from multiple ports, operates on the records with matching keys using a multiinput transform function and writes the result into output ports
In join the key parameter has to be specified from input flow (either of the flow) ascending or descending order. If all the input flows do not have any common field, override-key must be specified to map the key specified
It has the following ports
in0: the input file is connected to this port
in1:the second input file is connected to this port .this in port will increase based on the no of input file
out :the output of join component is going to this out port
Unused0:In this file contains the unused data (unmatched data) from the input file0
Unused1:In this file contains the unused data (unmatched data) from the input file1
Reject port :it contains the rejected record due to some error in the data from the file
Error port : It contains about detail description of rejection of the data .it write what is error in the file
Log port:It writes the process status based on the time until the process end.
It has three types of join as follows
1. Inner join (default) — Sets the record-requiredn parameters for all ports to True. The GDE does not display the record-requiredn parameters, because they all have the same value.
2. Outer join — Sets the record-requiredn parameters for all ports to False. The GDE does not display the record-requiredn parameters, because they all have the same value.
3. Explicit — Allows you to set the record-requiredn parameter for each port individually
REFORMAT:
Reformat changes the record format of data records by dropping fields, or by using DML expressions to add fields, combine fields, or transform the data in the records
By default reformat has got one output port but incrementing value of count parameter number. But for that two different transform functions has to be written for each output port.
If any selection from input ports is required the select parameter can be used instead of using ‘Filter by expression’ component before reformat
The Reformat component:
1. Reads records from the in port.
2. If you supply an expression for the select parameter, the expression filters the records on the in port:
a) If the expression evaluates to 0 for a particular record, Reformat does not process the record, which means that the record does not appear on any output port.
b) If the expression produces NULL for any record, Reformat writes a descriptive error message and stops execution of the graph.
c) If the expression evaluates to anything other than 0 or NULL for a particular record, Reformat processes the record.
3. If you do not supply an expression for the select parameter, Reformat processes all the records on the in port.
4. Passes the records to the transform functions, calling the transform function on each port, in order, for each record, beginning with out port 0 and progressing through out port count - 1.
5. Writes the results to the out ports
ROLLUP:
Rollup generates data records that summarize groups of data records on the basis of key specified.
Parts of Aggregate
• Input select (optional)
• Initialize
• Temporary variable declaration
• Rollup (Computation)
• Finalize
• Output select (optional)
Input_select : If it is defined , it filters the input records.
Initialize: rollup passes the first record in each group to the initialize transform function.
Temporary variable declaration:The initialize transform function creates a temporary record for the group, with record type temporary_type.
Rollup (Computation): Rollup calls the rollup transform function for each record in a group, using that record and the temporary record for the group as arguments. The rollup transform function returns a new temporary record.
Finalize:
If you leave sorted-input set to its default, Input must be sorted or grouped:
• Rollup calls the finalize transform function after it processes all the input records in a group.
• Rollup passes the temporary record for the group and the last input record in the group to the finalize transform function.
• The finalize transform function produces an output record for the group.
• Rollup repeats this procedure with each group.
Output select: If you have defined the output_select transform function, it filters the output records.
SCAN:
1. For every input record, Scan generates an output record that includes a running, cumulative summary for the data records group that input record belongs to. For example, the output records might include successive year-to-date totals for groups of data records
2. The input should be sorted before the scan else it produce error .
3. The main difference between Scan and Rollup is Scan generates intermediate (cumulative) result and Rollup summarizes
in0: the input file is connected to this port
in1:the second input file is connected to this port .this in port will increase based on the no of input file
out :the output of join component is going to this out port
Unused0:In this file contains the unused data (unmatched data) from the input file0
Unused1:In this file contains the unused data (unmatched data) from the input file1
Reject port :it contains the rejected record due to some error in the data from the file
Error port : It contains about detail description of rejection of the data .it write what is error in the file
Log port:It writes the process status based on the time until the process end.
It has three types of join as follows
1. Inner join (default) — Sets the record-requiredn parameters for all ports to True. The GDE does not display the record-requiredn parameters, because they all have the same value.
2. Outer join — Sets the record-requiredn parameters for all ports to False. The GDE does not display the record-requiredn parameters, because they all have the same value.
3. Explicit — Allows you to set the record-requiredn parameter for each port individually
REFORMAT:
Reformat changes the record format of data records by dropping fields, or by using DML expressions to add fields, combine fields, or transform the data in the records
By default reformat has got one output port but incrementing value of count parameter number. But for that two different transform functions has to be written for each output port.
If any selection from input ports is required the select parameter can be used instead of using ‘Filter by expression’ component before reformat
The Reformat component:
1. Reads records from the in port.
2. If you supply an expression for the select parameter, the expression filters the records on the in port:
a) If the expression evaluates to 0 for a particular record, Reformat does not process the record, which means that the record does not appear on any output port.
b) If the expression produces NULL for any record, Reformat writes a descriptive error message and stops execution of the graph.
c) If the expression evaluates to anything other than 0 or NULL for a particular record, Reformat processes the record.
3. If you do not supply an expression for the select parameter, Reformat processes all the records on the in port.
4. Passes the records to the transform functions, calling the transform function on each port, in order, for each record, beginning with out port 0 and progressing through out port count - 1.
5. Writes the results to the out ports
ROLLUP:
Rollup generates data records that summarize groups of data records on the basis of key specified.
Parts of Aggregate
• Input select (optional)
• Initialize
• Temporary variable declaration
• Rollup (Computation)
• Finalize
• Output select (optional)
Input_select : If it is defined , it filters the input records.
Initialize: rollup passes the first record in each group to the initialize transform function.
Temporary variable declaration:The initialize transform function creates a temporary record for the group, with record type temporary_type.
Rollup (Computation): Rollup calls the rollup transform function for each record in a group, using that record and the temporary record for the group as arguments. The rollup transform function returns a new temporary record.
Finalize:
If you leave sorted-input set to its default, Input must be sorted or grouped:
• Rollup calls the finalize transform function after it processes all the input records in a group.
• Rollup passes the temporary record for the group and the last input record in the group to the finalize transform function.
• The finalize transform function produces an output record for the group.
• Rollup repeats this procedure with each group.
Output select: If you have defined the output_select transform function, it filters the output records.
SCAN:
1. For every input record, Scan generates an output record that includes a running, cumulative summary for the data records group that input record belongs to. For example, the output records might include successive year-to-date totals for groups of data records
2. The input should be sorted before the scan else it produce error .
3. The main difference between Scan and Rollup is Scan generates intermediate (cumulative) result and Rollup summarizes
Partition Components

Broadcast:
broadcast arbitrarily combines all the data records it receives into a single flow and writes a copy of that flow to each of its output flow partitions 1. Reads records from all flows on the in port
2. Combines the records arbitrarily into a single flow
3. Copies all the records to all the flow partitions connected to the out port
Partition by Expression:
Partition by Expression distributes data records to its output flow partitions according to a specified DML expression. The output port for Partition by Expression is ordered
Partition by Key :
Partition by Key distributes data records to its output flow partitions according to key values. Reads records in arbitrary order from the in port
Distributes them to the flows connected to the out port, according to the key parameter, writing records with the same key value to the same output flow
Partition by percentage:
Partition by Percentage distributes a specified percentage of the total number of input data records to each output flow
Reads records from the in port
Writes a specified percentage of the input records to each flow on the out port
Partitions by Round robin:
1. Partition by round-robin distributes blocks of data records evenly to each output flow in round-robin fashion. Partitioning key is not required.The difference between Partition by Key and Partition by Round Robin is the 1st one may not distribute data uniformly across the all partition in a multi file system but the latter does
2. It first Reads records from the input file.
3. Then distributes them in block_size (specified no.of records)chunks to its output flows according to the order in which the flows are connected
Partition by Range:
Partition by range partition or divide the record based on the specified range in the file.for example consider the file contains 50records and it has four output file .i want 20 records in output 1and 5 records in output 2 & 3 remaining records in output4 then we can specify the range in the parameter tab.
Use the same key specifier for both components.
Make the number of partitions on the flow connected to the out port of Partition by Range the same as the value (n) in the num_partitions parameter of Find Splitters.
This component
Reads splitter records from the split port, and assumes that these records are sorted according to the key parameter.
Determines whether the number of flows connected to the out port is equal to n (where n-1 represents the number of splitter records).If not, Partition by Range writes an error message and stops the execution of the graph.
Reads data records from the flows connected to the in port in arbitrary order.
Distributes the data records to the flows connected to the out port according to the values of the key field(s), as follows:
a) Assigns records with key values less than or equal to the first splitter record to the first output flow.
b) Assigns records with key values greater than the first splitter record, but less than or equal to the second splitter record to the second output flow, and so on.
Partition by load balance:
Partition with Load Balance distributes data records to its output flow partitions by writing more records to the flow partitions that consume records faster.
The output port for Partition with Load Balance is ordered
broadcast arbitrarily combines all the data records it receives into a single flow and writes a copy of that flow to each of its output flow partitions 1. Reads records from all flows on the in port
2. Combines the records arbitrarily into a single flow
3. Copies all the records to all the flow partitions connected to the out port
Partition by Expression:
Partition by Expression distributes data records to its output flow partitions according to a specified DML expression. The output port for Partition by Expression is ordered
Partition by Key :
Partition by Key distributes data records to its output flow partitions according to key values. Reads records in arbitrary order from the in port
Distributes them to the flows connected to the out port, according to the key parameter, writing records with the same key value to the same output flow
Partition by percentage:
Partition by Percentage distributes a specified percentage of the total number of input data records to each output flow
Reads records from the in port
Writes a specified percentage of the input records to each flow on the out port
Partitions by Round robin:
1. Partition by round-robin distributes blocks of data records evenly to each output flow in round-robin fashion. Partitioning key is not required.The difference between Partition by Key and Partition by Round Robin is the 1st one may not distribute data uniformly across the all partition in a multi file system but the latter does
2. It first Reads records from the input file.
3. Then distributes them in block_size (specified no.of records)chunks to its output flows according to the order in which the flows are connected
Partition by Range:
Partition by range partition or divide the record based on the specified range in the file.for example consider the file contains 50records and it has four output file .i want 20 records in output 1and 5 records in output 2 & 3 remaining records in output4 then we can specify the range in the parameter tab.
Use the same key specifier for both components.
Make the number of partitions on the flow connected to the out port of Partition by Range the same as the value (n) in the num_partitions parameter of Find Splitters.
This component
Reads splitter records from the split port, and assumes that these records are sorted according to the key parameter.
Determines whether the number of flows connected to the out port is equal to n (where n-1 represents the number of splitter records).If not, Partition by Range writes an error message and stops the execution of the graph.
Reads data records from the flows connected to the in port in arbitrary order.
Distributes the data records to the flows connected to the out port according to the values of the key field(s), as follows:
a) Assigns records with key values less than or equal to the first splitter record to the first output flow.
b) Assigns records with key values greater than the first splitter record, but less than or equal to the second splitter record to the second output flow, and so on.
Partition by load balance:
Partition with Load Balance distributes data records to its output flow partitions by writing more records to the flow partitions that consume records faster.
The output port for Partition with Load Balance is ordered
- Reads records in arbitrary order from the flows connected to its in port
- Distributes those records among the flows connected to its out port by sending more records to the flows that consume records faster
3. Partition with Load Balance writes data records until each flow's output buffer fills up
Miscellaneous Components:

GATHER LOG
Gather log used to collects the output from the log ports of components for analysis of a graph after execution
Gather log used to collects the output from the log ports of components for analysis of a graph after execution
- Collects log records generated by components through their log ports.
- Writes a record containing the text from the StartText parameter to the file specified in the LogFile parameter.
- Writes any log records from its in port to the file specified in the LogFile parameter.
- Writes a record containing the text from the End Text parameter to the file specified in the LogFile parameter
LEADING RECORDS:
Leading record is used to copies the specified no of record from the in port and write into the out port counting from the first record of the file
REPLICATE:
Replicate arbitrarily combines all the data records it receives into a single flow and writes a copy of that flow to each of its output flows
Leading record is used to copies the specified no of record from the in port and write into the out port counting from the first record of the file
REPLICATE:
Replicate arbitrarily combines all the data records it receives into a single flow and writes a copy of that flow to each of its output flows
- Arbitrarily combines the data records from all the flows on the in port into a single flow
- Copies that flow to all the flows connected to the out port
GENERATE RECORDS:
Generate Records generates a specified number of data records with fields of specified lengths and types.
Generate Records generate random values within the specified length and type for each field, or you can control various aspects of the generated values. Typically, you would use the output of Generate Records to test a graph
Generate Records generates a specified number of data records with fields of specified lengths and types.
Generate Records generate random values within the specified length and type for each field, or you can control various aspects of the generated values. Typically, you would use the output of Generate Records to test a graph
- Generates the number of data records specified in the num_records parameter.
- Writes the records to its out port.